Blended Retrieval Is Here: How to Win When AI Agents Arrive With Your Customer’s Private Context
AI agents won’t visit your site as “blank” users anymore. They’ll arrive carrying private context from file stores, CRMs, and user documents—and your content will compete against that. Here’s what changes, why it matters for SMEs and agencies, and the practical, execution-first playbook to earn citations and conversions anyway.

AI Search didn’t just change how answers are generated. It changed what your website is competing against.
In the classic SEO world, you competed with other pages on the public web. In the emerging agentic world, your next “visitor” may be an AI agent that arrives carrying the customer’s private context—documents, file stores, CRM records, purchase history, preferences, and more—and then decides whether your page adds anything useful to the final answer.
That is the shift underneath blended retrieval, described in a recent Search Engine Journal analysis. Even if you’re not seeing the traffic yet, the architecture is the leading indicator: when vendors connect private sources to web retrieval inside a single reasoning loop, “Ranking” becomes a different game.
This editorial is the practical playbook for SMEs, marketing teams, and agencies: what changed, why it matters, what breaks, and what to do—especially when execution (not strategy decks) becomes the bottleneck.
Concise summary
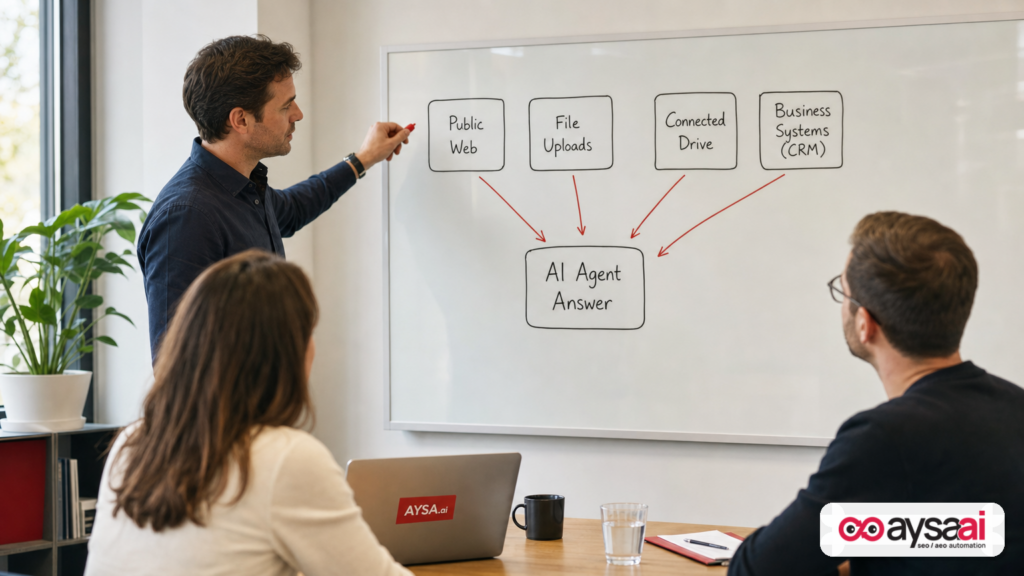
- AI agents are becoming a primary visitor class—and they may arrive with private context the user has authorized (files, drives, business systems).
- Blended retrieval changes the calculus: your page competes not only with other sites, but with the user’s own data sources that may be cleaner and more complete.
- Machine-first wins citations: clear entity relationships, canonical identity, Structured data, and rendering that doesn’t hide content.
- Some queries will bypass websites entirely when private sources suffice—so your job is to publish what private data can’t: explainers, policies, live availability, authoritative specs, proof, and decision support.
- Execution is the moat: continuous technical cleanup + content structuring beats one-time audits.
Key takeaways for business owners

- Stop thinking “keywords.” Start thinking “mergeable facts.” Can an agent extract your pricing, eligibility, availability, and policies without guessing?
- Structure is leverage. If your data is messy, the agent will lean on other sources—including the customer’s own documents.
- Your differentiator must be something the user’s private context doesn’t already contain. If you only restate generic info, you’ll be skipped.
- Build pages for two readers: humans and agents. Human-friendly does not mean unstructured; it means clear plus machine-readable.
- Operationally, you need a system to monitor and ship changes. AI search visibility becomes a product of how fast you implement improvements.
Table of contents

- What changed: the “private-context visitor” becomes normal
- Why this matters to SMEs (and not just enterprise)
- The new ranking problem: you’re competing with the customer’s own data
- Blended retrieval explained in plain English
- What breaks first: the usual SEO playbook pitfalls
- What websites must become: machine-first, human-friendly
- Content that still wins in an agentic world
- Concrete SME scenario: an ecommerce store vs. a shopper’s receipts
- Measurement reality: what you can and can’t see
- What agencies should rethink (offers, deliverables, reporting)
- Where AYSA.ai fits: monitored, approved execution for AI search
- What to do next: a 30/60/90-day action list
- Sources and further reading
What changed: the “private-context visitor” becomes normal
The web has always had multiple visitor types: humans, crawlers, scrapers, feed readers, and API clients. AI agents add a new class—one that reasons, retrieves, and composes answers. That part is already familiar.
The bigger change is that the agent may arrive with context that never existed in classic web search:
- User-provided files (PDFs, reports, contracts)
- Connected file stores (drives, enterprise document systems)
- Connected business systems (CRMs, billing tools, inventory systems) via consented connectors
In other words, your site is no longer the primary container of truth. It’s one candidate source among many—some of which may be more accurate for that specific user than anything you can publish.
Search Engine Journal’s piece frames it clearly: when blended retrieval runs, the agent arrives with private context already fused into the query, and your page is judged by whether it adds something that private sources did not.
Even if today this capability is limited to certain product tiers or early previews (and is not yet the majority of your analytics), the direction is hard to ignore. Major vendors tend to converge on architectures that work.
Why this matters to SMEs (and not just enterprise)
If you run a local business, ecommerce brand, or SaaS company, it’s tempting to think this is “big tech stuff” that only affects Fortune 500 research teams.
It won’t stay that way, because:
- Consumers already use AI for decisions (what to buy, where to book, what provider to choose), and product UX tends to trickle down fast.
- Small businesses are over-indexed on being “explained” by third parties (directories, review sites, marketplaces). If agents prefer clean sources, those intermediaries may get cited more than you.
- SME sites are often structurally messy—theme-heavy WordPress builds, JS-rendered ecommerce, inconsistent naming, stale hours/pricing. In blended retrieval, messiness is punished harder because the agent has better alternatives.
There’s also a strategic reason: SMEs can move faster. Enterprises have data silos, legal reviews, and massive CMS constraints. If you can ship improvements weekly, you can win disproportionate citation share—even in competitive categories—because AI systems reward clarity and extractability.
The new ranking problem: you’re competing with the customer’s own data
Classic SEO competition looked like this:
- Your page vs. competitor pages
- Search engine Ranking Signals decide visibility
- User Clicks and reads your page
In blended retrieval, a more realistic competition looks like this:
- Your page vs. competitor pages
- Your page vs. the customer’s own private sources (documents, account history, a connected system)
- The agent decides what to cite, summarize, or ignore
This is subtle but brutal: you can’t “optimize against” the private sources because you can’t see them. You can only control how cleanly your site’s signal can be extracted and fused with everything else.
So the right business question becomes:
Is this page contributing something an agent can’t already get from the user’s own data?
If your answer is “we basically repeat generic definitions,” you’re building pages that blended retrieval will route around.
Blended retrieval explained in plain English
Blended retrieval is not just “AI reads the web.” It’s “AI reads the web and private, user-authorized sources inside one reasoning loop.”
A simplified flow looks like this:
- The user asks an AI assistant a question (for example: “Which plan should I choose, and what will it cost me this year?”).
- The user has connected sources (maybe a file store with last year’s receipts and a finance tool export).
- The agent retrieves from those private sources, retrieves from the public web, then fuses them into a single answer.
In a web-only world, your pricing page might be the main source. In blended retrieval, the agent might already have the customer’s exact usage history and contract terms. Your generic pricing tables could be irrelevant—unless you add decision support, edge-case clarity, exceptions, and machine-readable constraints.
The SEJ article points to the Model Context Protocol (MCP) as an important connector standard for exposing private sources to agents through user consent. MCP is associated with Anthropic (as noted in the source article), and the main takeaway for operators is not the protocol name—it’s that private systems are becoming “retrievable” in the same way websites are.
When private sources are retrievable, the “default advantage” websites used to have (being the only accessible reference) shrinks.
What breaks first: the usual SEO playbook pitfalls
Plenty of classic SEO guidance still matters: clear pages, strong brand, good UX, real authority. But several common habits degrade quickly in the blended-retrieval era.
Pitfall 1: Keyword pages that don’t add new information
Pages built to “match queries” but not to answer decisions will get less valuable. Agents can generate generic explanations instantly. If your page is interchangeable with a model’s base knowledge, it becomes optional.
Pitfall 2: JavaScript-heavy rendering that hides the payload
Agents and crawlers are improving, but the most reliable extraction still comes from straightforward HTML, stable DOM, and predictable content placement. If key information is loaded late, gated behind interactions, or split across app states, your signal becomes expensive to retrieve—and agents will prefer cheaper, cleaner sources.
Pitfall 3: Inconsistent entity identity across the web
If your business name, address, product names, SKUs, or plan tiers vary by channel, agents struggle to reconcile. In blended retrieval, reconciliation matters more because the agent is trying to merge multiple sources into a single coherent answer.
Pitfall 4: Stale “truth” (hours, inventory, pricing, eligibility)
Private sources can be current. If your public site is stale, it will be treated as lower-confidence. For local businesses, stale hours and policies are a silent killer; for ecommerce, stale inventory and shipping details are.
Pitfall 5: Unstructured pages with “pretty prose” but no extractable facts
Beautiful copy doesn’t help an agent if it can’t confidently extract constraints (price ranges, availability, requirements, comparisons, warranties, return windows). Structure isn’t just a technical preference—it’s how you earn citation share in AI answers.
What websites must become: machine-first, human-friendly
I’ll say the quiet part out loud: the next phase of “SEO” looks less like marketing and more like publishing infrastructure.
When the visitor is an agent, the winner is the site that is:
- Canonical: one true URL per entity, product, location, plan, policy.
- Consistent: the same fields mean the same things across pages.
- Structured: clear entity relationships, structured data where appropriate, obvious headings and tables.
- Rendering-independent: essential content is present without fragile client-side dependencies.
- Fresh: the site’s “truth layer” is updated as the business changes.
Notice what’s not on the list: “write 200 blog posts.” Content volume is not the same thing as usable signal.
This is aligned with the SEJ piece’s emphasis on clean entity relationships, canonical identity, live data, and rendering independence as higher-leverage inputs when agents are fusing sources.
Structured data: where it helps and where it won’t
Structured data is not magic. It doesn’t force citations. It does, however, reduce ambiguity.
When your public site must be blended with private context, ambiguity is the enemy. If your product offer is scattered across paragraphs, an agent may misread it. If it’s expressed in structured form (and reinforced by clear on-page text), extraction becomes safer.
The SEJ analysis highlights structured Product and Offer data as the kind of structured information that tends to be cited more cleanly than unstructured descriptions in blended scenarios. That’s intuitive: offers are constraints, and constraints are what decision-making agents need.
Where it won’t help: using structured data to restate generic claims (like “best quality” or “top rated”) without proof. Agents can’t merge fluff. They merge facts.
Entity relationships: the overlooked foundation
Entity relationships are simply “how things relate”:
- This product belongs to this brand.
- This plan applies to these use cases.
- This location offers these services.
- This policy applies under these conditions.
Humans infer relationships. Agents prefer them explicitly stated.
If you run a clinic, don’t just list services—connect services to insurance types accepted, appointment types, provider credentials, and next-available slots. If you run ecommerce, connect products to compatibility constraints, model numbers, shipping cutoffs, and returns policy.
Content that still wins in an agentic world
If some answers can be produced from private sources alone, does that mean “content is dead”? No. It means the content that wins changes.
Here’s the practical split:
What private context can often answer without you
- User’s past purchases and receipts
- User’s contract terms and usage history
- Internal business policies (for enterprise users)
- User’s calendar constraints, preferences, travel plans
If your pages only repeat what’s already in those sources, you’ll be skipped.
What your website should provide that private sources usually can’t
- Authoritative, current public truth: Inventory status, next-available appointments, shipping timelines, pricing rules, exceptions.
- Decision support: comparison tables, “choose this if…” logic, calculators, eligibility rules.
- Proof: certifications, warranties, clinical outcomes disclosures (when appropriate), third-party validation, transparent reviews policies.
- Interpretation: explaining edge cases, tradeoffs, and what changes under different conditions.
- Clear, quotable policies: returns, cancellation, refunds, SLAs—written in plain language and also extractable.
Agents love content that reduces risk and uncertainty. That’s where citations happen.
Humanize without becoming unstructured
One mistake I see is swinging from “SEO copy” to “brand storytelling” and losing the payload.
You can humanize and still be machine-first:
- Use short paragraphs and specific headings (“What’s included”, “What it costs”, “Who it’s for”, “What to expect”).
- Add an FAQ that addresses real objections (not vanity questions).
- Include examples and scenarios with explicit constraints (timeframes, eligibility, geography).
- Keep a single source of truth for policy and pricing; reuse it consistently.
Concrete SME scenario: an ecommerce store vs. a shopper’s receipts
Let’s make blended retrieval tangible with a realistic ecommerce scenario.
Business: a mid-sized online retailer selling water filters and replacement cartridges.
Customer question to an agent: “Which replacement filter do I need, and should I buy a subscription?”
In a blended retrieval world, the agent might have private context like:
- An email receipt from last year that includes the filter housing model
- A photo or PDF of the manual stored in a connected drive
- The customer’s past reorder intervals
Now ask: what can your website add that the customer’s private context doesn’t already provide?
If your product page is generic (marketing copy, no compatibility table, no model crosswalk, no clear difference between variants), your site becomes a low-confidence source. The agent will prefer the manual or the receipt.
If your product page is machine-first, you win citations and conversions:
- A compatibility matrix: housing model → cartridge SKU
- A reorder interval guide (“most customers replace every X months depending on usage”)
- Subscription logic: savings, skip/pause rules, reminders, cancellation policy
- Clear identifiers (SKU, UPC, model numbers) that match what appears on receipts and manuals
- Live shipping cutoffs and in-stock status
In this situation, the agent can merge: “receipt says model A,” + “site says model A uses cartridge B,” + “customer replaced every 5 months,” + “subscription every 5 months saves $X.” Your site becomes the bridge that turns private context into a purchase.
This is the heart of the new game: don’t fight private context—complete it.
Measurement reality: what you can and can’t see
Most teams will struggle here, because blended retrieval breaks familiar measurement assumptions.
You often can’t see what you’re competing with
You won’t know whether the agent relied on:
- An uploaded document
- A connected drive file
- A private business system connector
So you can’t build a classic competitive analysis around it.
What you can track
- Visibility signals: whether your brand and URLs appear in AI-generated answers (AEO/GEO monitoring).
- Technical extractability: crawlability, renderability, structured data validity, canonical correctness.
- Conversion readiness: whether pages provide decision-support elements (comparisons, calculators, policies) that turn an AI citation into an action.
- Content drift: places where your public truth is stale or inconsistent across pages.
If you want a single mindset shift: measure “answer contribution,” not just clicks.
Some of your best outcomes will be assist outcomes—the agent uses your data to decide, then sends fewer but more qualified visits. That’s still revenue.
What agencies should rethink (offers, deliverables, reporting)
Agencies and consultants are going to feel this transition in their packaging before they feel it in their dashboards.
Deliverables need to become “shippable,” not “auditable”
In 2018, an audit PDF felt valuable. In 2026, audits without execution are dead weight.
If blended retrieval raises the bar for clean structure, the winning agency offer looks like:
- Ongoing technical hygiene (rendering, canonicals, schema validation, internal linking)
- Entity cleanup across the site and brand footprint
- Content upgrades tied to decision points (not “top-of-funnel volume”)
- Citation/mention monitoring in AI answers (AEO/GEO)
- A tight implementation loop with approvals
Reporting needs to include AI visibility, not just Google clicks
If your clients only see GA4 sessions and Search Console clicks, you’re under-reporting reality. You need a way to communicate:
- Where the brand is being cited (or not)
- Which pages are being used as source material
- Which improvements were shipped and why
Not because “AI is cool”—but because it shapes purchase decisions upstream.
Where AYSA.ai fits: monitored, approved execution for AI search
This is exactly the environment AYSA.ai is built for: the execution-heavy, continuous-improvement reality of AI search.
Most teams don’t fail because they lack ideas. They fail because:
- They don’t monitor consistently.
- They don’t know what to fix first.
- They can’t ship changes fast (or safely) due to approvals and bandwidth.
AYSA is an execution system that:
- Monitors your site and visibility patterns over time: AYSA Monitoring
- Prepares recommended changes for AI search visibility and technical clarity: AI Search Visibility
- Asks for approval before implementation—so you control what ships (critical for SMEs that can’t risk breaking revenue pages).
- Executes accepted changes so improvements don’t sit in a backlog.
If you’re exploring “AI SEO tools,” start here: AI SEO Tools
If you need to align on cost and scope: AYSA Pricing
And if you want more operator-level thinking, our editorial archive is here: AYSA Blog
AYSA’s point of view: the moat is “structural predictability”
Here’s my opinion, and I’ll stand behind it: in blended retrieval, structural predictability becomes a competitive moat.
Not “AI tricks.” Not prompt engineering. Not content volume.
Structural predictability means:
- Your entities are unambiguous.
- Your pages are consistent templates with consistent fields.
- Your offers and policies are extractable.
- Your rendering is reliable.
- Your data is kept current.
This is not glamorous work—but it’s compounding work. Every improvement makes future retrieval more reliable, and reliability is what agents reward when they have alternatives.
What to do next: a 30/60/90-day action list
This is the part that matters. Here’s an execution-first plan that works for most SMEs and lean marketing teams.
Days 0–30: stabilize the “truth layer”
- Inventory your money pages: products, services, locations, pricing, booking pages, policies.
- Fix canonical identity: one primary URL per product/service/location; remove or consolidate duplicates where feasible.
- Make key facts visible without fragile rendering: pricing ranges, availability, hours, lead times, shipping/returns/cancellation basics.
- Start structured data hygiene: validate and correct the basics relevant to your business (do not spam).
- Align names and fields: product names, SKUs, plan tiers, service names should match what customers see on invoices/receipts.
If you want a system to keep this moving (and not die in a spreadsheet), this is where AYSA Monitoring fits operationally.
Days 31–60: build decision support agents can cite
- Create comparison assets: plan comparisons, product comparison tables, “which service is right for me” pages.
- Add “edge case” clarity: exceptions and constraints (eligibility, geography, timing, what’s not included).
- Publish policy pages that are quotable: clean headings, bullet points, clear time windows, clear definitions.
- Improve internal linking by intent: connect FAQ → policy → offer → checkout/booking.
This is where AI visibility starts to shift: you’re no longer publishing for “impressions,” you’re publishing for “mergeable decisions.”
Days 61–90: operationalize freshness and consistency
- Set ownership: who updates pricing, hours, inventory notes, availability, policies.
- Add change workflows: approvals, QA, release schedule.
- Monitor AI citations/mentions: where does the brand show up, and which pages are cited?
- Iterate templates: create standard page structures for products/services/locations so future pages are machine-first by default.
In most organizations, this is where execution collapses—too many stakeholders, too many CMS constraints, not enough time. AYSA’s model (prepare → request approval → execute) is built to reduce that friction while keeping you in control.
What to do next (quick checklist)
- Pick 10 revenue-driving pages and rewrite them for extractable clarity (headings, tables, FAQs, constraints).
- Fix your entity identity: consistent naming, consistent URLs, consistent structured data.
- Make the payload crawlable and renderable without relying on late-loading interactions.
- Add decision-support assets that private context can’t replace (comparisons, exceptions, “choose this if…” guides).
- Start monitoring AI visibility and ship improvements monthly—not quarterly.
- Adopt an execution system so work gets approved and implemented (not trapped in audits).
Sources and further reading
- Search Engine Journal: Your Next AI Visitor Will Know Who Sent It (primary research input for this editorial)
- Search Engine Journal: SEO section
- Search Engine Journal: Latest news
- Search Engine Journal: Local SEO section
- Search Engine Journal: Enterprise SEO section
Note: The source article references vendor announcements and the Model Context Protocol (MCP) as context for blended retrieval. This editorial does not add new quantitative claims beyond the supplied source context. If you’re evaluating vendor-specific capabilities, confirm details in each vendor’s official documentation.
Learn more about AYSA.ai
Continue the AI search topic inside AYSA.
Use these pages to connect the article with AI SEO tools, AI visibility monitoring, AI Overviews and approved website execution.
Turn this topic into a website action plan.
Use these AYSA hubs to move from reading to technical fixes, AI visibility monitoring, research, glossary context and approval-first SEO execution.

